Вступ
У семінарі №3 ви дізнаєтесь про дебагер GDB (ваш кращий друг!), навчитеся реалізовувати (програмувати) алгоритм бінарного пошуку та різні алгоритми сортування:
- Сортування бульбашкою (Bubble sort)
- Сортування вибором (Selection sort)
- Сортування вставкою (Insertion sort)
- Сортування злиттям (Merge sort)
GDB (GNU Project Debugger)
Що це таке?
GDB - це засіб для налагоджування програм або "дебагер". Налагоджування або "дебаг" загалом - це процес пошуку та усунення помилок у коді. Для того, щоб знайти помилки, треба якимось чином дізнатись, як виконується програма та які значення мають змінні в будь-який момент роботи програми. Це можна легко зробити за допомогою спеціального інструмента - дебагера.
Одним із них і є GDB: завдяки ньому можна не використовувати printf кожного разу, коли ви хочете знайти помилку.
Команди GDB
GDB працює лише на виконуваних файлах. Для запуску GDB, просто наберіть у командному рядку:
gdb [ім'я програми]
Відкриється командний рядок для дебагера програми. У ньому ви можете вводити одну з наступних команд (і не лише їх):
run [аргументи командного рядка програми]
Запустити програму.
-
break [номер рядка/ім'я функції]
Встановити точку зупинки програми на певному рядку або функції.
next
Перейти на наступний рядок, не заходячи всередину функцій.
step
Перейти на наступний рядок. Якщо на рядку виклик функції - зайти всередину неї.
list
Вивести код програми навколо поточного місця.
print [змінна]
Вивести значення змінної на екран.
info locals
Вивести усі локальні (поточні) змінні: всередині циклу, функції абощо. Зручно, щоб не вводити підряд декілька команд print
display [змінна]
Виводитиме значення змінної на кожному кроці дебагу.
help
Показати список усіх команд GDB.
Приклади
Запуск дебагера:
gdb [ім'я програми]
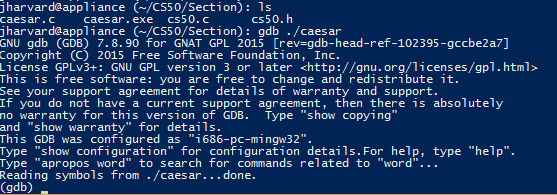
-
break
У програмі caesar є одна функція, main. Встановимо точку зупинки програми на функції main:

run
Запустимо програму caesar з аргументом "3":

print
Припустимо, нам треба перевірити значення argc:

next
Продовжимо покроково виконувати програму далі:
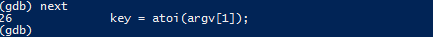
Тут відбувається присвоєння значення змінній key. Перевіримо, яке значення вона має на цьому рядку:

Чому "0"? Адже ми ввели "3"? Річ у тому, що присвоєння відбувається саме на цьому рядку. Команду просто ще не було виконано. Щоб її виконати, треба ввести next ще раз:

Коли ми знову введемо next, то почне виконуватись функція GetString(). Вона очікує на введення даних з клавіатури, тому треба щось ввести:

Виконавши команду next ще раз, зайдемо всередину циклу і опинимося на умові:

info locals
Як програма повинна виконуватись далі? Щоб дізнатись це, нам потрібно переглянути значення усіх локальних змінних (тих, що існують в межах циклу):

Умову буде виконано, і, увівши next ще декілька разів, ми виконаємо інструкції всередині циклу, і опинимося на початку наступної ітерації циклу:
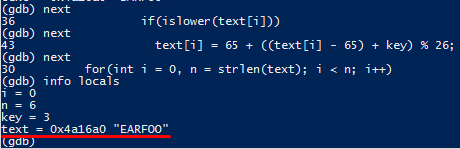
Зверніть увагу, що змінилось значення змінної text.
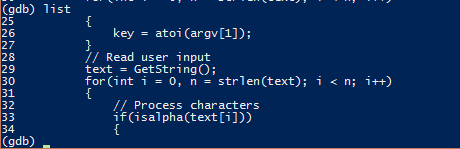
list
Подивимось код біля того рядка, де ми зупинились:
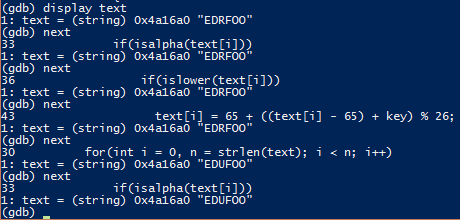
display
Щоб відловити момент, коли змінюється значення змінної text, необхідно використати команду display:
help
Приклад:
Бінарний пошук

Алгоритм бінарного пошуку базується на принципі "розділяй і володарюй". Якщо значення середини масиву співпадає з шуканим шуканим значенням, то ми вже знайшли його позицію. Якщо ж не співпадає, то потрібно з'ясувати, чи воно знаходиться у лівій чи правій частині масиву.
Якщо шукане значення менше значення в середині масиву, то необхідно шукати його в лівій частині, інакше - в правій, за таким самим принципом, як і спочатку: розділивши відповідну частину на дві половини, і т. д.
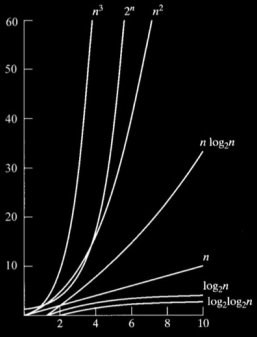
На рисунку нижче зображено асимптотичну складність (швидкість роботи за різної кількості вхідних значень) простого алгоритму пошуку, та алгоритму бінарного пошуку.
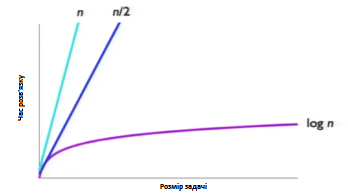
Для простого алгоритму складність - N (швидко зростає), для бінарного пошуку - log(n) (зростає повільно).
Приклад роботи алгоритму
Необхідно знайти у масиві число 7:
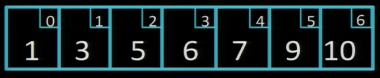
Спершу, подивимось в середину масиву (чи array[3] більше, менше або рівне 7?):
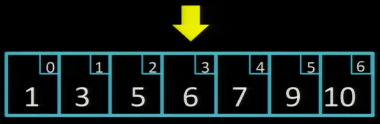
Значення 6 менше ніж шукане число 7, тому ліву частину масиву можна відкинути і продовжити пошук у правій частині. Тепер перевірятимемо значення array[5]:
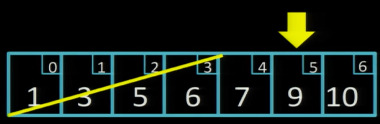
Оскільки 9 більше за шукане 7, шукатимемо далі у лівій половині:
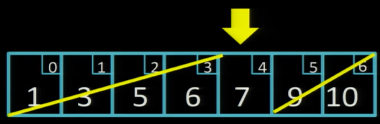
Ось ми і знайшли шукане значення, всього лише за 3 кроки!
Для семи вхідних значень розв'язок можна знайти у найгіршому випадку за 3 кроки. Для чотирьох мільярдів вхідних значень - лише за 32 кроки! (2^32 ~ 4 000 000 000)
Кодування алгоритму
Вправа
Нижче подано заготовку функції бінарного пошуку. Необхідно доповнити її власним кодом:
/** * Повертає значення true, якщо значення value є в масиві * values, інакше - false. */ bool search(int value, int values[], int n) { // Встановити значення верхньої і нижньої межі пошуку int lower = 0; int upper = n - 1; while(lower <= upper) { // Що треба робити тут? } return false; }
Бінарний пошук - узагальнення
- Найкращий випадок - Ω(1)
- Найгірший випадок - O(log n)
- Вхідний список повинен бути відсортованим
Сортування бульбашкою
В алгоритмі сортування бульбашкою, ви просто проходите по масиву і послідовно порівнюєте числа. Якщо перше з них більше за друге, то вони міняються місцями.
Алгоритм
- Пройти по всьому списку значень, міняючи місцями сусідні значення, якщо вони не впорядковані;
- Повторити крок 1, якщо було зроблено хоча б один обмін.
Приклад
Застосуємо алгоритм сортування бульбашкою, щоб впорядкувати за зростанням такий масив:
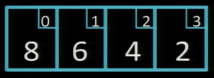
Прохід 1
Здійснюємо три обміни (червоним виділено елементи, що порівнюються):
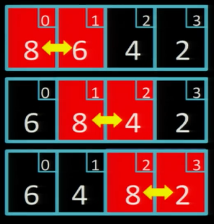
Прохід 2
Оскільки на проході 1 ми здійснили обмін, то робимо ще один прохід (тут також здійснюємо три обміни):
Прохід 3
Лише один обмін:
Хоча після цього проходу масив вже впорядковано, але оскільки був зроблений обмін, необхідно зробити ще один прохід.
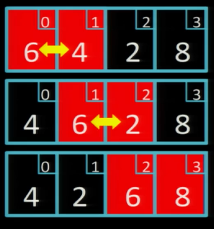
Прохід 4
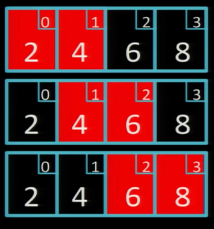
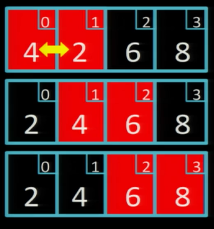
Це останній прохід, бо масив вже впорядковано і ми не зробили жодного обміну значень.
Псевдокод
Ініціалізувати лічильник повторювати { Встановити лічильник на 0 Пройти в циклі весь масив якщо n-те значення більше за n+1-ше обміняти їх місцями збільшити лічильник } поки (лічильник > 0)
Кодування алгоритму
Вправа
Нижче подано заготовку функції сортування бульбашкою. Необхідно доповнити її власним кодом:
void sort(int array[], int n) { //Циклічний прохід по масиву for(int k = 0; k < n - 1; k++) { //Оптимізація: перевірка на здійснення обмінів int swaps = 0; //обміняти сусідні елементи, якщо вони не впорядковані //Пройтися по масиву if(!swaps) break; } }
Сортування бульбашкою - узагальнення
- Найгірший випадок - O(n2)
- Найкращий випадок - Ω(n)
- Примітивний і повільний алгоритм сортування.
Сортування вибором
Алгоритм
- Знайти найменше невпорядковане значення.
- Поміняти це значення місцями з першим невпорядкованим значенням.
- Повторити з кроку 1, якщо ще є невпорядковані значення.
Приклад
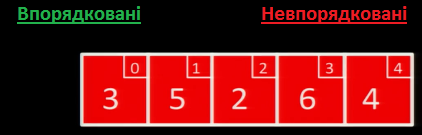
Впорядкуємо за зростанням масив, зображений нижче.
На початку роботи алгоритму, всі значення є невпорядкованими.
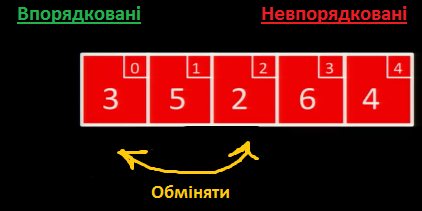
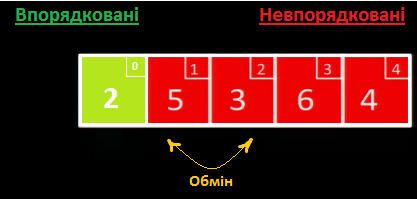
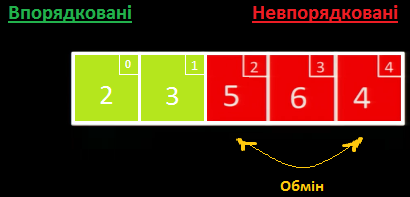
Шукаємо у масиві найменше невпорядковане значення. Це - 2, тому ми міняємо його місцями із першим невпорядкованим значенням 3:
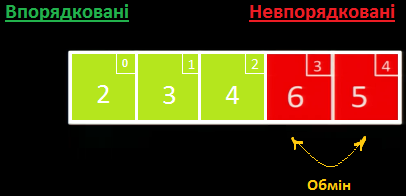
Далі ми обробляємо лише невідсортовану частину:
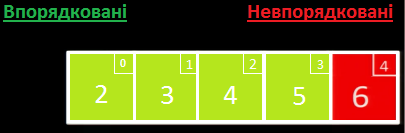
Отже, масив упорядковано.
Псевдокод
Для i в межах від 0 до n-2 min = i для j в межах від i+1 до n-1 якщо array[j] < array[min] min = j якщо min != i обмін array[min] та array[j]
Кодування алгоритму
Вправа
Нижче подано заготовку для функції сортування вибором. Необхідно доповнити її, щоб отримати робочий алгоритм.
/** * Сортування масиву із використанням сортування вибором. */ void sort(int array[], int size) { //Пройти по масиву for(int i = 0; i < size - 1; i++) { //Найменший елемент у відсортованій частині //Пройти по невідсортованій частині масиву // Знайти наступний найменший елемент //Обміняти місцями int temp = array[i]; array[i] = smallest; array[position] = temp; } }
Сортування вибором - узагальнення
- Найгірший випадок - O(n2)
- Найкращий випадок - Ω(n2)
- Простий і легкий в реалізації алгоритм, проте менш ефективний ніж сортування включенням.
Сортування включенням
На кожному кроці алгоритму сортування включенням ми вибираємо один з елементів вхідних даних і вставляємо його на потрібну позицію у вже відсортованому списку до тих пір, доки набір вхідних даних не буде вичерпано. Метод вибору чергового елементу з початкового масиву довільний; може використовуватися практично будь-який алгоритм вибору. Зазвичай (і з метою отримання стійкого алгоритму сортування), елементи вставляються за порядком їх появи у вхідному масиві.
Алгоритм
Для кожного невпорядкованого елемента n:
- Визначити позицію n у впорядкованій частині масиву
- Зсунути впорядковані елементи вправо так, щоб звільнити місце для n
- Вставити n у впорядковану частину масиву.
Псевдокод
Для і в межах від 0 до n - 1 element = array[i] j = i поки ((j > 0) та array[j-1] > element) array[j] = array[j - 1] j = j - 1 array[j] = element
Приклад
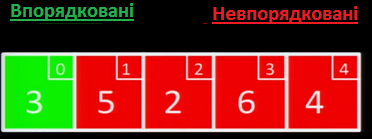
Як і в алгоритмі сортування вибором, спершу всі елементи масиву є невпорядкованими.

На першій ітерації алгоритму, ми беремо перше значення із масиву, і вставляємо його у список впорядкованих значень
Далі, на другій ітерації алгоритму, ми беремо перше значення у невідсортованій частині масиву, і починаємо шукати для нього підходяще місце у вже відсортованій частині масиву. Оскільки 5 > 3, то ми вставляємо нове значення праворуч від старого.
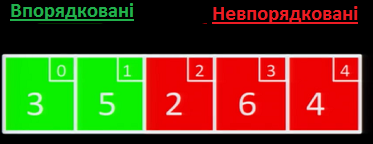
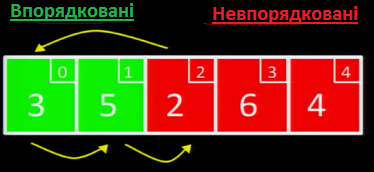
На наступній ітерації, ми беремо значення 2. Оскільки 2 < 5 та 2 < 3, необхідно вставити 2 ліворуч 3 та 5. Щоб зробити це, ми посуваємо трійку та п'ятірку праворуч, і вставляємо двійку на її місце:
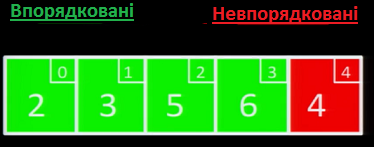
Оскільки наступний елемент, 6, - найбільше значення у відсортованій частині масиву, вставляємо її праворуч від 5.
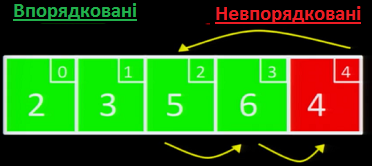
Останній елемент, 4, - менший за 5 та 6, але більший за 3 - тому ми вставляємо його між 3 та 5.
Масив відсортовано.
Сортування включенням - узагальнення
- Найгірший випадок - O(n2)
- Найкращий випадок - Ω(n)
- Алгоритм ефективний, коли потрібно відсортувати частково впорядкований масив.
Сортування злиттям
Сортування злиттям — рекурсивний алгоритм сортування, в основі якого лежить принцип «Розділяй та володарюй». В основі цього способу сортування лежить злиття двох упорядкованих ділянок масиву в одну впорядковану ділянку іншого масиву.
Рекурсивна функція - це така функція, що викликає саму себе.
Алгоритм
Для масиву з n елементів на вході:
- Якщо n < 2 - закінчити виконання (масив з одного чи нуля елементів вже впорядкований)
- Інакше:
- Відсортувати праву половину масиву
- Відсортувати ліву половину масиву
- Злити відсортовані половини.
Приклад
Розбиваємо на половинки, доки у кожному підмасиві опиниться лише один елемент.

Далі ми починаємо зливати ці підмасиви, формуючи з них відсортований більший масив. Під час злиття ми знаходимо, у якому з двох підмасивів перший елемент менший, видаляємо цей елемент і вставляємо у кінець злитого масиву, доки підмасиви не стануть пустими.
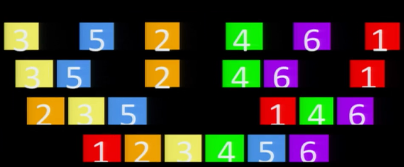
Вправа
Необхідно доповнити функцію merge своїм кодом так, щоб працювала функція sort.
void sort(int array[], int start, int end) { if(end > start) { int middle = (start + end) / 2; sort(array, start, middle); sort(array, middle + 1, end); merge(array, start, middle, middle+1, end); } } void merge (int array[], int start_1, int end_1, int start_2, int end_2) { // Виконайте злиття відсортованих підмасивів, використовуючи допоміжний масив temp }void sort(int array[], int start, int end) { if(end > start) { int middle = (start + end) / 2; sort(array, start, middle); sort(array, middle + 1, end); merge(array, start, middle, middle+1, end); } } void merge (int array[], int start_1, int end_1, int start_2, int end_2) { // Виконайте злиття відсортованих підмасивів, використовуючи допоміжний масив temp }
Сортування злиттям - узагальнення
- Найгірший випадок - O(nlogn)
- Найкращий випадок - Ω(nlogn)
- Алгоритм сортування злиттям працює значно швидше за інші, розглянуті у цьому конспекті (як видно з графіка нижче)