Вступ
У семінарі №6 розглянуто принципи побудови таких структур даних:
- Зв'язані списки
- Хеш-таблиці
- Префіксні дерева
- Дерева
- Бінарні дерева
- Стек
- Черга
Зв'язний список
Визначення
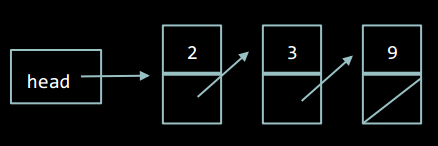
Зв'язний список - це структура даних, в якій елементи лінійно впорядковані, але порядок визначається не номерами елементів (як в масивах), а вказівниками, що входять у склад елементів списку та вказують на наступний елемент. Список має "голову" (перший елемент) та "хвіст" (останній елемент).
Переваги і недоліки порівняно з масивами
На відміну від масивів, вставка та вилучення елементів у Зв'язний список потребують сталого часу (О(1)). Також значною перевагою зв'язних списків є можливість легкого розширення: щоб збільшити розмір списку, треба лише додати ще один елемент.
Недоліком зв'язних списків є необхідність проходити весь список, щоб знайти елемент (тобто час доступу до елемента списку - О(n)).
Елемент зв'язаного списку
Елемент зв'язаного списку містить дані та посилання (покажчик) на наступний елемент списку, або NULL, - якщо цей елемент є останнім.
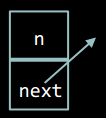
Нижче наведено код структури, що реалізує елемент зв'язаного списку (і власне список). Дані представлені числовим значенням.
typedef struct node { int n; struct node* next; } node;
Пошук по списку
Для пошуку елемента у списку, необхідно пройти весь список. Це реалізується за допомогою переходу з поточного елемента на наступний за посиланням.
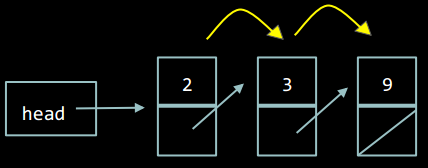
У цьому прикладі для того, щоб знайти елемент "9", необхідно перш за все з голови списку перейти на елемент "2". Потім за посиланням перейти на елемент "3". Лише після цього можна за посиланням знайти елемент "9".
Нижче наведено код функції, яка шукає заданий елемент у списку і повертає true, якщо елемент є у списку, або false, якщо елемента немає у списку.
bool search (node* list, int n) { node* ptr = list; while (ptr != NULL) { if(ptr -> n == n) { return true; } ptr = ptr -> next; } return false; }
Вставка елемента у список
Є три різні можливі варіанти вставки у список: вставка у початок списку, вставка у кінець списку і вставка у якесь місце всередині списку.
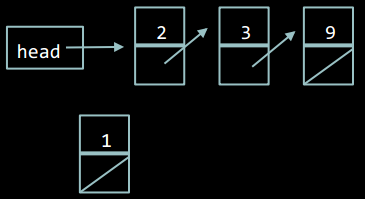
Розглянемо вставку в початок списку (оскільки це найбільш часто використовуваний варіант вставки).
-
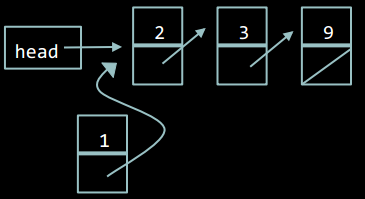
Створимо новий елемент. Він поки що не посилається на інші елементи, і на нього ніякий інший елемент не посилається.
-
Переназначити покажчик нового елементу так, щоб він вказував на той же елемент, на який вказує head.
-
Переназначити покажчик head на новий елемент.
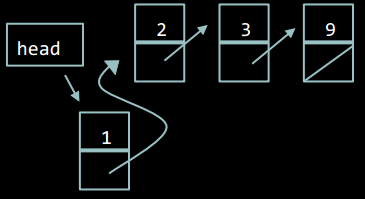
Важливо зробити кроки 2 і 3 саме в такому порядку. Якщо спершу встановити head на новий елемент, то ми втратимо частину списку.
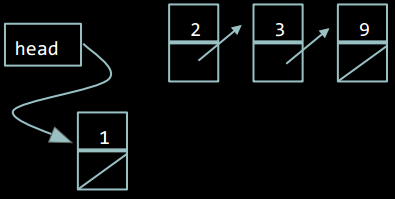
Нижче наведено код функції для вставки нового елементу на початок списку.
void insert(int n) { //створити новий елемент node* new = malloc(sizeof(node)); //перевірка на NULL if(new == NULL) { exit(1); } //ініціалізувати новий елемент new->n = n; new->next = NULL; //вставити новий елемент у голову списку new->next = head; head = new; }
Двозв'язний список
Двозв'язний список схожий на звичайний Зв'язний список, але елементи у ньому зберігають посилання не лише на наступний, а й на попередній елемент. Завдяки цій властивості, можна переміщуватись по списку вперед і назад.
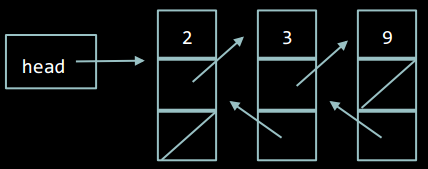
Елемент двозв'язного списку
Елемент двозв'язного списку містить дані та два поля: prev та next, - покажчики на попередній та наступний елементи списку відповідно.
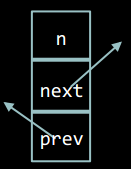
Код структури елемента двозв'язного списку мовою С:
typedef struct node { int n; struct node* next; struct node* prev; } node;
Хеш-таблиці
Поняття хеш-таблиці
Хеш-таблиця - це, масив, у якому місце розташування елемента залежить від значення, яке має сам елемент. Зв'язок між значенням елемента і його позицією у хеш-таблиці задає хеш-функція. Важлива властивість хеш-таблиці: пошук, вставка і видалення елементів з таблиці виконуються за час О(1).
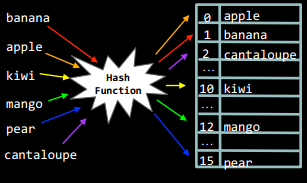
У прикладі вище, позиція кожного слова в хеш-таблиці залежить від порядкового номеру першої букви цього слова в англійському алфавіті.
Поняття хеш-функції
Загалом, хеш-функцією можна вважати таку функцією, що приймає якийсь елемент (який потрібно вставити у хеш-таблицю), а результатом її роботи є позиція заданого елемента у хеш-таблиці.
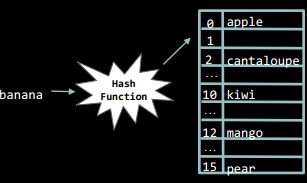
Приклади: порядковий номер першої букви слова у алфавіті, остача від ділення на 13, тощо.
Нижче наведено код хеш-функції на основі першої літери в рядку:
int hash_function(char* key) { int hash = toupper(key[0]) - 'A'; return hash % SIZE; }
Колізії
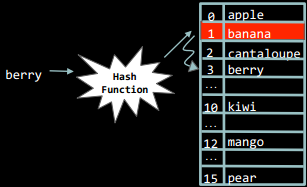
Ситуація, коли для різних ключів отримується одне й те саме хеш-значення, називається колізією. Наприклад, у зображену раніше таблицю на основі перших символів рядка ми спробуємо додати нове слово - berry.
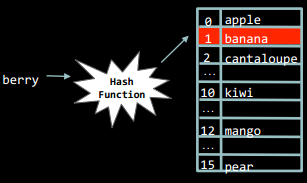
Але у комірці, яку повернула хеш-функція, вже є значення. Але ж все одно нове значення потрібно кудись записати, і для цього потрібно визначити, куди саме його буде записано. Це називається розв'язанням колізії.
Лінійне зондування
Один з варіантів розв'язання колізій - лінійне зондування, коли просто відбувається пошук першої пустої комірки після тої, на яку вказала хеш-функція.
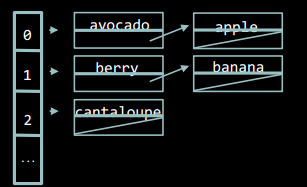
Метод ланцюжків
При методі ланцюжків, кожна комірка хеш-таблиці - це список значень. При виникненні колізії, нове значення просто додається до списку у ту ж саму комірку таблиці.
Префіксне дерево
Префіксне дерево - це структура даних, в якій шлях від кореня дерева до листка (останнього елемента) дерева визначає рядок.
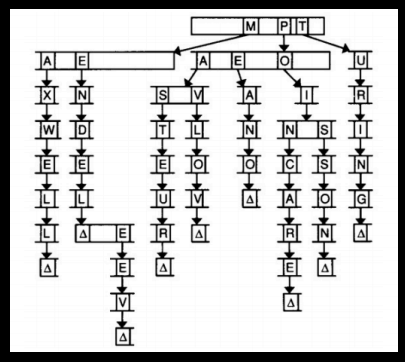
Таким чином, при проходженні дерева згори донизу формуються слова.
Опис структури префіксного дерева
typedef struct node { // Маркер кінця слова bool is_word; // Покажчики на інші елементи struct node* children[27]; } node;
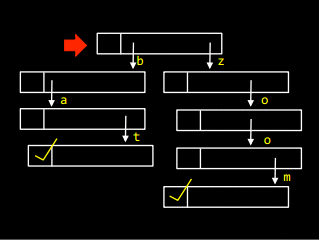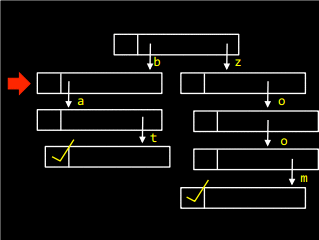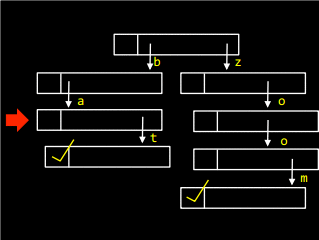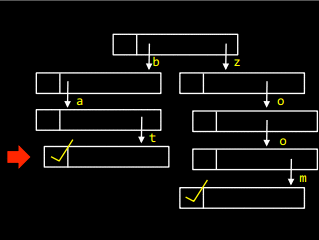
Приклад роботи із префіксним деревом
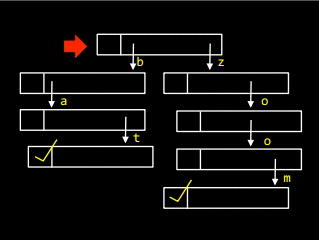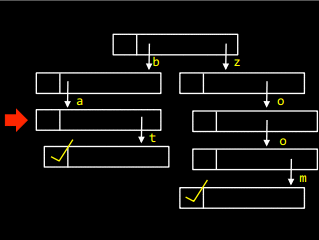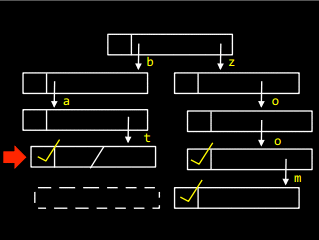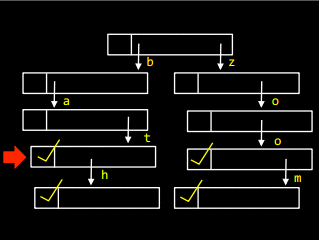
Маємо наступного виду префіксне дерево, у якому є слова bat та zoom:
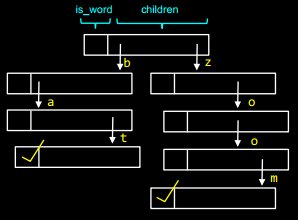
Переходячи за послідовними посиланнями згори донизу доти, доки не зустрінемо маркер кінця слова, отримаємо слово bat:
Для того щоб вставити слово zoo у масив, необхідно пройти по списку і встановити маркер:
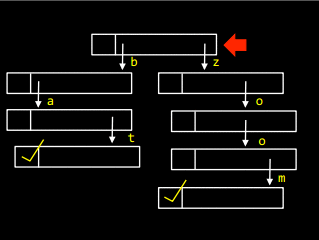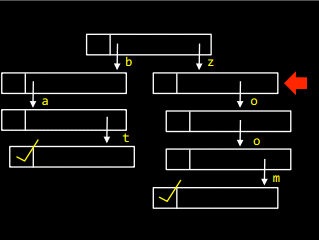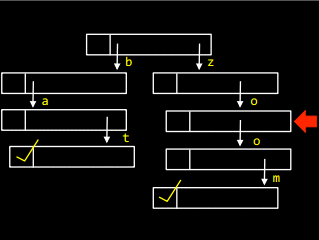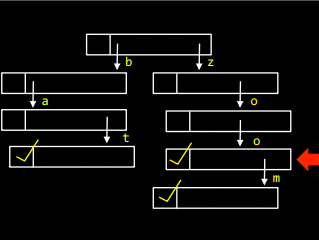
А щоб додати у дерево слово bath, треба в останньому елементі слова bat створити посилання, що вказує на букву h:
Дерева
Дерево - це структура даних, де елемент, або вузол, вказує на інші вузли. Приклад дерева:
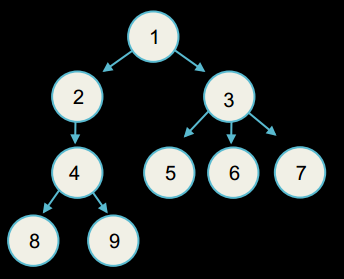
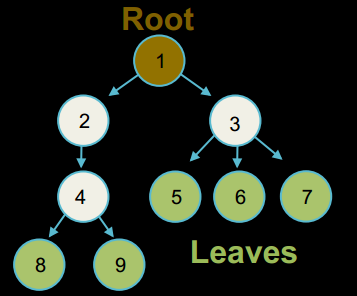
Корінь дерева - верхній вузол у дереві (1 у прикладі)
Батько - вузол, що вказує на вузол, який ви розглядаєте. Наприклад, батько вузла 3 - вузол 1.
Нащадок - вузол, на який вказують інші вузли (так, у прикладі вузли 2 та 3 є нащадками вузла 1).
Листки дерева - вузли, що знаходяться знизу, або вузли, що не мають нащадків.
Брати і сестри - це вузли, що мають спільного батька (у прикладі, вузли 5, 6, 7).
Бінарні дерева
Бінарне дерево - це дерево, у якому кожен вузол має не більше двох нащадків.
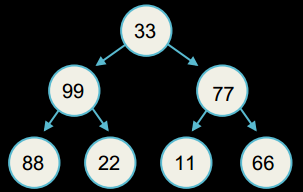
Елемент бінарного дерева
Бінарне дерево, як і однозв'язний або двозв'язний список, оголошуються за допомогою свого елемента. У бінарному дереві, кожен елемент має дані (ціле число у прикладі), і посилання на лівого та правого нащадків:
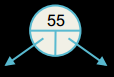
typedef struct node { int n; struct node* left; struct node* right; } node;
Бінарне дерево пошуку
У бінарному дереві пошуку все, що справа від батьківського вузла - більше за нього, а все, що зліва - менше.
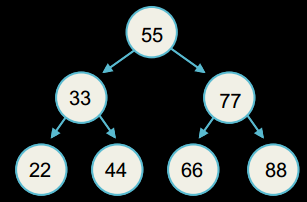
Таким чином, пошук елемента в бінарному дереві пошуку дуже схожий на пошук елемента в масиві за алгоритмом бінарного пошуку. Єдина різниця - при пошуку в бінарному дереві, замість лівої або правої половини масиву ми щоразу розглядаємо ліве або праве піддерево.
Нижче наведено код функції пошуку елемента у бінарному дереві пошуку.
bool search(node* root, int val) { if(root == NULL) return false; if(root->n == val) return true; if(val < root->n) return search(root->left, val); if(val > root->n) return search(root->right, val); }
Стек
Стек - це структура даних, яка працює за принципом "останнім прийшов - першим пішов" (first in - first out, FIFO). Можна уявити собі стіс розносів у їдальні - той рознос, що поклали у стіс останнім, новий клієнт їдальні забере в першу чергу.

LIFO - це абревіатура, яка означає "last in - first out", тобто "останнім прийшов - першим пішов".
Над стеком можна здійснювати дві операції - push (занесення даних) і pop (вилучення даних).
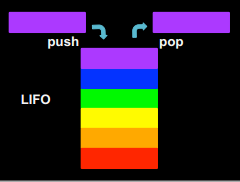
Приклад реалізації стеку мовою С наведено нижче. У цьому прикладі, стек - це просто масив рядків, що має певну ємність (CAPACITY), і поточний розмір (size):
typedef struct{ char* strings[CAPACITY]; int size; } stack;
Щоб реалізувати операцію push, необхідно зробити перевірку, чи не перевищує поточний розмір ємність стеку, після чого - вставити елемент на позицію size і збільшити size на одиницю.
Для реалізації операції pop, необхідно перевірити, чи не пустий стек, зменшити поточний розмір на одиницю і повернути елемент.
Черга
Черга - це структура даних, що працює за принципом "першим прийшов - першим пішов" (last in - first out, LIFO).
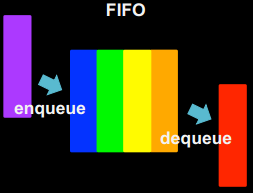
Для черги визначено дві операції - додавання елемента в кінець черги (enqueue) та вилучення елемента з початку черги (dequeue).
У прикладі оголошено чергу, що фактично являє собою масив рядків:
typedef struct{ int head; char* strings[CAPACITY] int size; } queue;
Щоб реалізувати операцію enqueue, необхідно впевнитись, що чергу не переповнено, додати елемент в кінець черги і збільшити поточний розмір на одиницю.
Щоб реалізувати операцію dequeue, треба впевнитись, що черга не пуста, збільшити head на одиницю, зменшити поточний розмір і повернути перший елемент черги.